
In machine learning, Supervised Learning is done using a ground truth, ie., we have prior knowledge of what the output values for our samples should be. Hence, the goal of supervised learning is to learn a function that, given a sample of data and desired outputs, best approximates the relationship between input and output observable in the data.(unsupervised learning, on the other hand, does not have labeled outputs, so its goal is to infer the natural structure present within a set of data points).

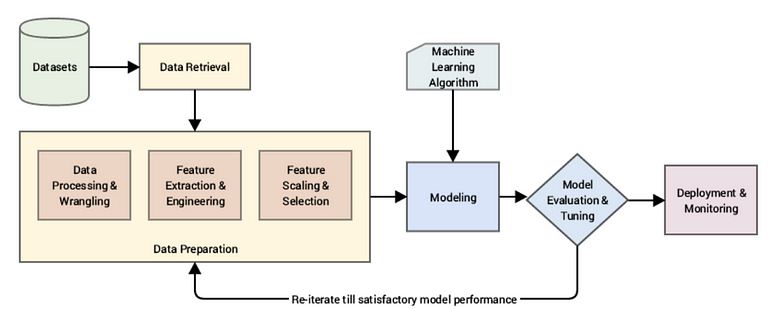
Let’s briefly describe a typical supervised learning workflow or pipeline, under the context of classification predictive analytics, for illustration purposes (such workflows or pipelines comprise the following steps, typically: ingestion of raw data, leverage data processing techniques to wrangle, process and engineer meaningful features and attributes from this data, leverage ML models to model on these features and then deploy the model for future usage based on the problem to be solved at hand).
It’s useful to lean into a known dataset in order to shed light into the workflow steps and provide concrete examples. For this purpose, let’s borrow for a moment the Iris flow dataset. It was put together by R. A. Fisher for discriminant analysis, circa 1936, and freely available at the UCI ML repository. It is of the most commonly used example datasets when in comes to introducing various concepts in data science.
The Iris dataset class labels are the 3 flower species: Setosa, Virginica, and Versicolor. Every one of the 150 instances in the dataset (ie., individual flowers) consists of four features: sepal width and length, and petal width and length (in cm).
Raw data collection and Feature Extraction
The Iris is a good dataset in the sense that it has no missing data, and it displays numeric features that can be used by a learning algorithm. But most often, it is required to remove sample rows of datasets that contain missing values (or attribute columns where data is missing). Better yet, one can use imputation to handle missing data (ie., replacement of missing values using certain statistics rather than complete removal). For categorical data, the missing value can be interpolated from the most frequent category, and the sample average can be used to interpolate missing values for numerical attributes. Other useful approaches related to feature extraction could include the aggregation of petal and sepal measurements (ex: ratios).
Sampling
Once main features are adequately extracted from raw data, next step is about splitting the dataset into a training and a test dataset. The training dataset will be used to train the model, and the purpose of the test dataset is to assess the performance of the final model.It is important that we use the test dataset only once in order to avoid overfitting when calculating prediction-error metrics (ie., good performance on training data but lack of generalization , hence driving high prediction-error on novel patterns. Therefore, techniques such as cross-validation are used in the model creation and refinement steps to check classification performance:
Therefore, techniques such as cross-validation are used in the model creation and refinement steps to check classification performance:
Therefore, techniques such as cross-validation are used in the model creation and refinement steps to check classification performance:Cross-validation
CV is a popular technique to evaluate different combinations of feature selection, dimensionality reduction, and learning algorithms. There are multiple flavors of cross-validation (most common one is the so-called “ k-fold cross-validation”).
In k-fold cross-validation, the original training dataset is split into k different subsets (ie., “folds”) where 1 fold is retained as test set, and the other k-1 folds are used for training the model.
Example: if we set k equal to 4 (i.e., 4 folds), 3 different subsets of the original training set would be used to train the model, and the 4th fold would be used for evaluation. After 4 iterations, it is possible to calculate the average error rate (and standard deviation) of the model, providing an idea of how well the model is able to generalize.

Normalization
Normalization (often used synonymous to “Min-Max scaling” — the scaling of attributes in a certain range, e.g., 0 to 1 ) and other feature scaling techniques are often required in order to make comparisons between different attributes (e.g., to compute distances or similarities in cluster analysis), especially, if the attributes were measured on different scales (ex: temperatures in Kelvin and Celsius). Adequate scaling of features is a requirement for vast majority of ML algorithms.

Feature Selection & Dimensionality Reduction
The main purpose of these two approaches is to remove noise, increase computational efficiency by retaining only “useful” (discriminatory) information, and to avoid overfitting (“curse of dimensionality”). In feature selection, we keep the “original feature axis”; dimensionality reduction usually involves a transformation technique.
In feature selection, we are interested in retaining only those features that are “meaningful” , helping to build a strong/good classifier. Feature selection is often based on domain knowledge and careful exploratory analyses (ex: through histograms or scatterplots). There are three common approaches to feature selection :(a) Filter, (b) Wrapper, (c) Embedding.


Commonly used dimensionality reduction techniques are linear transformations such as Principal Component Analysis (PCA) and Linear Discriminant Analysis (LDA).
.
PCA can be described as an “unsupervised” algorithm, since it ignores class labels and its goal is to find the directions (the so-called principal components) that maximize the variance in a dataset.
In contrast to PCA, LDA is understood as being “supervised” ,computing the directions (“linear discriminants”) that will represent the axes that maximize the separation between multiple classes.
 Learning algorithms and tuning of hyper-parameters
Learning algorithms and tuning of hyper-parametersThere are is a broad array of different learning algorithms. A (highly) summarized list of common supervised learning algorithms could include:
-Support Vector Machine (SVM) → classification method that samples hyperplanes which separate between two or multiple classes. Eventually, the hyperplane with the highest margin is retained (“margin” = the minimum distance from sample points to the hyperplane). The sample point(s) that form margin are called support vectors and establish the final SVM model.
-Bayes classifiers → based on a statistical model (Bayes theorem: calculating posterior probabilities based on the prior probability and the so-called likelihood). A Naive Bayes classifier assumes that all attributes are conditionally independent, thereby, computing the likelihood is simplified to the product of the conditional probabilities of observing individual attributes given a particular class label.
-Decision tree classifiers → tree like graphs, where nodes in the graph test certain conditions on a particular set of features, and branches split the decision towards the leaf nodes. Leaves represent lowest level in the graph and determine the class labels. Optimal tree are trained by minimizing impurity (gini) — or maximizing information gain.
-Regression → tries to fit data with the best hyper-plane which goes through the points; output is a real or continuous value. Linear regression is most common type.
-Artificial Neural Networks (ANN) → graph-like classifiers that are a simplified proxy for the structure of an animal “brain” (interconnected nodes ~neurons).

Hyper-parameters are the parameters of the model that are not directly learned in the ML step from the training data -they are optimized separately. The goals of hyper-parameter optimization are to improve the performance of the model (in this example, a classification model) and to achieve good generalization of a learning algorithm. A popular method for hyper-parameter optimization is Grid Search. After all possible parameter combination for a model are evaluated, the best combination will be retained.
Prediction Error and Model Selection
A convenient tool for performance evaluation is the so-called Confusion Matrix → a square matrix that consists of columns and rows that list the number of instances as “actual class” vs. “predicted class” ratios.
The prediction “accuracy” or “error” is used to report classification performance.
→ Accuracy is defined as the fraction of correct classifications out of the total number of samples; it is often used synonymous to specificity/precision although it is calculated differently.
→ Empirical Error of a classification model can be calculated by 1-Accuracy.
In practice, the choice of an appropriate prediction-error metric tends to be task-specific.
Example of Confusion Matrix
Another convenient way to fine-tune a classifier in context of a binary classification problem such as “email spam” classification is the Receiver Operating Characteristic (ROC, or ROC curve).
Example — ROC Analysis
Other indicators for classification performances are
Sensitivity and Precision → assess the “True Positive Rate” for a binary classification problem, ie probability to make a correct prediction for a “positive/true” case.
Specificity → describes the “True Negative Rate” for a binary classification problem, ie probability to make a correct prediction for a “false/negative” case.

Thank you
0 Response to "Supervised Learning"
Post a Comment