
As we have seen the machine learning terminology previously, let us see the deep learning terminology now.


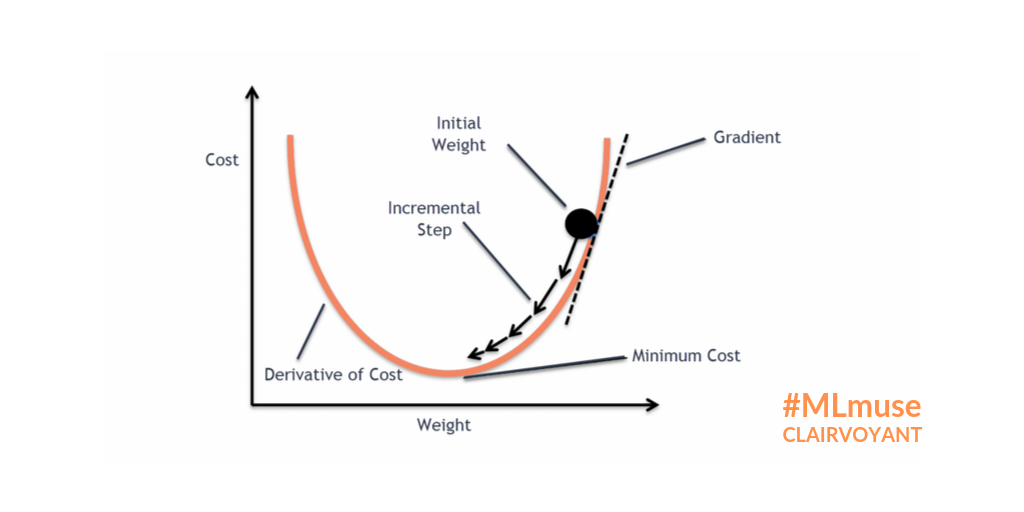 Backpropagation
Backpropagation
Activation function:
In neural networks, the activation function produces the output decision boundaries by combining the network's weighted inputs. Activation functions range from identity (linear) to sigmoid (logistic, or soft step) to hyperbolic (tangent) and beyond. In order to employ backpropagation (see below), the network must utilize activation functions which are differentiable.Different Activaton functions will be shown in next article.
Area under the ROC Curve (AUC):
The AUC is the area under the ROC curve and is a performance measure that tells you how well your model can classify different classes. The higher the AUC the better the model.
Batch
A batch is a fixed number of examples used in one training iteration during the model training phase.
Gradient descent
Gradient descent is the basic algorithm used to minimize the loss based on the training set. It’s an iterative process through which the parameters of your model are adjusted and thereby gradually finding the best combination to minimize the loss.
BackpropagationBackpropagation is shorthand for “the backward propagation of errors” and is the main algorithm used to calculate the partial derivative of the error for each parameter in a neural network.
Batch gradient descent
Batch gradient descent is an implementation of gradient descent which computes the real gradient of the loss function by taking into account all the training examples.
Batch normalization
Batch normalization standardizes the output of a previous activation layer by subtracting the batch mean and dividing by the batch standard deviation.
This helps speed up the training of the network. It also makes the network learn to generalize, as it introduces a small controlled amount of noise in the inputs of the subsequent layer.
Classification
Classification is the process through which a trained model predicts (or assigns) one or several classes for one example.
Cost Function
When training a neural network, the correctness of the network's output must be assessed. As we know the expected correct output of training data, the output of training can be compared. The cost function measures the difference between actual and training outputs. A cost of zero between the actual and expected outputs would signify that the network has been training as would be possible; this would clearly be ideal.
Multi-label classification
Multi-label classification is a variant of classification where multiple classes (labels) may be assigned to each example.
Single-label classification
Single-label classification is a variant of classification where precisely one class (label) is assigned to each example.
Clustering
Clustering is the process through which an algorithm tries to group data points into different clusters based on some similarity between them.
Convolution
In deep learning a convolution operation is a mathematical operation between a matrix and another smaller matrix called the filter, where each element of the matrix is multiplied by the filter.
Convolutional layer
A convolutional layer applies the convolution operation between its filters and its input.
Deconvolution
Deconvolution performs an opposite operation to the convolution operation. This is also referred to as transposed convolution, which better reflects the actual mathematical operation.
The deconvolution operation is used when we transform the output of a convolution back into a tensor that has the same shape as the input of that convolution.
Deconvolutional layer
A deconvolutional layer applies the deconvolution between its filters and its input.
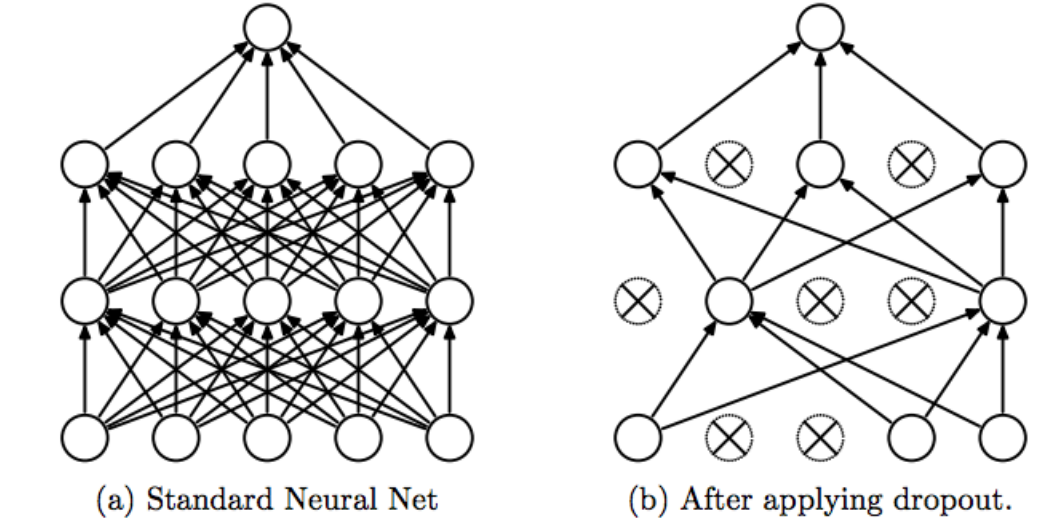
Dropout
Dropout is a regularization technique which randomly zeros out (i.e. “drops out”) some of the weights in a given layer during each training iteration.
Epoch
An epoch represents a full pass over the entire training set, meaning that the model has seen each example once.
Generalization
Generalization is the ability of a model to perform well on data / inputs it has never seen before. The goal of any model is to learn good generalization from the training examples, in order to later on perform well on examples it has never seen before.
Hidden layer
A hidden layer is any layer in a neural network between the input layer and the target.
Hyperparameter
A hyperparameter is any parameter of a model or training process that has to be set / fixed before starting the training process, i.e., they are not automatically adjusted during the training.
Input layer
The input layer is the first layer of a neural network and is the one which take the individual examples of your training set as input to the model.
Learning rate
The learning rate is a hyperparameter of gradient descent. It’s a scalar which controls the size of the update steps along the gradient.
Choosing the right learning rate is crucial for optimal gradient descent.
Loss
Loss is a measure of how well your algorithm models your dataset. It’s a numeric value which is computed by the loss function. The lower the loss, the better the performance of your model.
Normalization
Normalization is the process of ‘resizing’ values (e.g., the outputs of a layer) from their actual numeric range into a standard range of values.
Optimizer (gradient descent)
An optimizer is a specific implementation of gradient descent which improve the performance of the basic gradient descent algorithm.
Oversampling
It’s the process of balancing a dataset by reusing examples of the underrepresented classes so that every class of the dataset has an equal amount of examples.
Padding
Padding is the process of adding one or more pixels of zeros all around the boundaries of an image, in order to increase its effective size.
Pooling
Pooling is the process of summarizing or aggregating sections of a given data sample (usually the matrix resulting from a convolution operation) into a single number. This is usually done by either taking the maximum or the average value of said sections.
Random uniform initialization
Random uniform initialization is a technique used to initialize the weights of your model by assigning them values from a uniform distribution with zero mean and unit variance.
Random uniform initialization helps generate values for your weights that are simple to understand intuitively.
Undersampling
It’s the process of balancing a dataset by discarding examples of one or more overrepresented classes so that each has the same amount of examples.
Vanishing Gradient Problem
Backpropagation uses the chain rule to compute gradients (by differentiation), in that layers toward the "front" (input) of an n-layer neural network would have their small number updated gradient value multiplied n times before having this settled value used as an update. This means that the the gradient would decrease exponentially, a problem with larger values of n, and front layers would take increasingly more time to train effectively.
Weight initialization
Weight initialization is the process of assigning some starting values to the weights of your model, before starting training.
The starting values of the weights have a significant impact on the training of your model.
***Thank You***
0 Response to "Deep Learning Terminology"
Post a Comment