
CatBoost is based on gradient boosting. A new machine learning technique developed by Yandex outperforms many existing boosting algorithms like XGBoost, Light GBM.
While deep learning algorithms require lots of data and computational power, boosting algorithms are still needed for most business problems. However, boosting algorithms like XGBoost takes hours to train, and sometimes you’ll get frustrated while tuning hyper-parameters.
On the other hand, CatBoost is easy to implement and very powerful. It provides excellent results in its very first run.
Base tree structure :
- One main difference between CatBoost and other boosting algorithms is that the CatBoost implements symmetric trees. This may sound absurd but helps in decreasing prediction time, which is extremely important for low latency environments.
- Default max_depth = 6
Procedure for other gradient boosting algorithms (XG boost, Light GBM)
Step 1: Consider all (or a sample ) the data points to train a highly biased model.
Step 2: Calculate residuals (errors) for each data point.
Step 3: Train another model with the same data points by considering residuals (errors) as target values.
Step 4: Repeat Step 2 & 3 ( for n iterations).
This procedure is prone to overfitting, because we are calculating residuals of each data point by using the model that has already been trained on same set of data points.
CatBoost Procedure
CatBoost does gradient boosting in a very elegant manner. Below is an explanation of CatBoost using a toy example.
Let’s say, we have 10 data points in our dataset and are ordered in time as shown below.
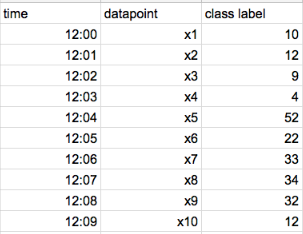
If data doesn’t have time, CatBoost randomly creates an artificial time for each datapoint.
- Step 1: Calculate residuals for each data point using a model that has been trained on all the other data points at that time (For Example, to calculate residual for x5 datapoint, we train one model using x1, x2, x3, and x4 ). We train different models to calculate residuals for different data points. In the end, we are calculating residuals for each data point that the model has never seen before.
- Step 2: Train a model by using the residuals of each data point as class values.
- Step 3: Repeat Step 1 & Step 2 (for n iterations)
For the above toy dataset, we should train 9 different models to get residuals for 9 data points. This is computationally expensive when we have many data points.
Hence by default, instead of training different models for each data point, it trains only log(num_of_datapoints) models. If a model has been trained on n data points then that model is used to calculate residuals for the next n data points.
- A model that has been trained on the first data point is used for calculating residuals of the second data point.
- Another model that has been trained on the first two data points is used for calculating residuals of the third and fourth data points and so on…
In the above toy dataset, we calculate residuals of x5,x6,x7, and x8 using a model that has been trained on x1, x2,x3, and x4.
The above procedure is known as ordered boosting.
Random Permutations
CatBoost divides a given dataset into random permutations and applies ordered boosting on those random permutations. By default, CatBoost creates four random permutations. With this randomness, we can further stop overfitting our model. We can further control this randomness by tuning parameter bagging_temperature. This is something that you have already seen in other boosting algorithms.
Handling Categorical Features.
- CatBoost has a very good vector representation of categorical data. It takes concepts of ordered boosting and applies the same to response coding.
- In response coding, we represent categorical features using the mean to the target values of the data points. We are representing a feature value of each data point by using its class label. This leads to target leakage.
- CatBoost considers only the past data points to calculate the mean value. Below is a detailed explanation with examples.
let’s take a toy dataset. (all the data points are ordered in time/day)
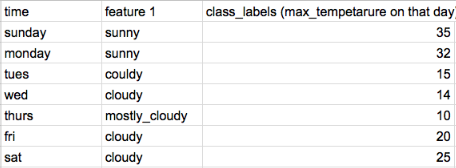
If data doesn’t have time, CatBoost randomly creates an artificial time for each datapoint.
We have feature 1, a categorical feature that has 3 different categories.
With response coding, we represent cloudy = (15 +14 +20+25)/4 = 18.5
This actually leads to target leakage. Because we are vectorising a data point using target value of the same datapoint.
CatBoost vectorize all the categorical features without any target leakage. Instead of considering all the data points, it will consider only data points that are past in time. For Example,
- On Friday, it represents cloudy = (15+14) /2 = 15.5
- On Saturday, it represents cloudy = (15+14+20)/3 = 16.3
- But on Tuesday, it represents cloudy = 0/0?
It implements Laplace smoothing to overcome zero by zero problem.
Below is one another neat example,
In the above dataset, we have a feature with two categories(SDE, PR), and let’s assume that all the data points are ordered in time. For ith data point, we represent SDE as (1+1+0)/3 (with some constant added to the numerator and denominator to overcome 0/0 error).
Categorical Feature Combinations
CatBoost combines multiple categorical features. For the most number of times combining two categorical features makes sense. CatBoost does this for you automatically.
In this dataset, there are two features (country and hair length). We can easily observe that whenever a person is from India, his/her hair color is black. We can represent those two features into a single feature. In the real world, multiple categorical features can be represented as a single feature.
CatBoost finds the best possible feature combinations and considers them as a single feature. Below is the neat diagram of CatBoost representing two features as a single feature at level 2 of the tree.
At the first level of the tree, we have a single feature. When the level of tree increases, the number of categorical feature combinations increases proportionally.
One-hot Encoding in CatBoost
By default, CatBoost represents all the two-categorical features with One-hot encoding.
- If you would like to implement One-hot encoding on a categorical feature that has N different categories then you can change parameter one_hot_max_size = N.
Handling Numerical Features
CatBoost handles the numerical features in the same way that other tree algorithms do. We select the best possible split based on the Information Gain.
Limitations
- At this point, CatBoost doesn’t support sparse matrices.
- When the dataset has many numerical features, CatBoost takes so much time to train than Light GBM.
CatBoost in various situations:
While Hyper-parameter tuning is not an important aspect for CatBoost, the most important thing is to set the right parameters based on the problem we are solving. Below are a few important situations.
1. When data is changing over time
We are living in the 21st century where the distribution of data changes recklessly over time. Especially in most of the internet companies, user preferences change over time to time. There are many situations in the real world where data changes over time. CatBoost can perform very well in these situations by setting parameter has_time = True.
2. Low latency requirements
Customer satisfaction is the most important aspect of every business. A user usually expects very fast service from the website/model. CatBoost is the only boosting algorithm with very less prediction time. Thanks to its symmetric tree structure. It is comparatively 8x faster than XGBoost while predicting.
3. Weighting data points
There are some situations where we need to give more importance to certain data points. Especially when you do a temporal train-test split, you need the model to train mostly on the earlier data points. When you give more weightage to a data point, It has a higher chance of getting selected in the random permutations.
We can give more weightage to certain data points by setting parameter
For example, you can give linear weightage all the datapoints
sample_weight = [ x for x in range(train.shape[0])]
4. Working with small datasets
There are some instances where you have fewer data points, but you need to minimize the loss. In those situations you can set parameters fold_len_multiplier as close as to 1 (must be >1) and approx_on_full_history =True . With these parameters, CatBoost calculates residuals for each data point using a different model.
5. Working with large datasets
For large datasets, you can train CatBoost on GPUs by setting parameter task_type = GPU. It also supports multi-server distributed GPUs. CatBoost also supports older GPUs that you can train in Google Colabs.
6. Monitoring Errors / Loss function
It’s a very good practice to monitor your model for every iteration. You can monitor any metrics of your choice along with your optimizing loss function by setting parameter custom_metric=[‘AUC’, ‘Logloss’].
You can visualize all the metrics that you have choosen to monitor. Make sure that you have installed ipywidgets using pip to visualize plots in Jupyter Notebook and set parameter plot = True.
7. Staged prediction & Shrinking Models
This is again one powerful method implemented by the CatBoost library. You have trained a model and you want to know how your model predicts at a particular iteration. You can call the staged_predict( ) method to check how your model performs at that stage. If you notice that in a particular stage that the model is performing better than your final trained model, then you can use a shrink( ) method to shrink the model to that particular stage.
8. Handling different situations
Whether it’s a festival season or week-end or a normal day, the model should predict the best results in every given situation. You can train different models on different cross-validation datasets and blend all the models using the sum_models( )
Many More…
- By default, CatBoost has an overfitting detector that stops training when CV error starts increasing. You can set parameter od_type = Iter to stop training your model after few iterations.
- We can also balance an imbalanced dataset with the class_weight parameter.
- CatBoost not only interprets important features, but it also returns important features for a given data point what are the important features.
- The code for training CatBoost is simply straight forwarded and is similar to the sklearn module. You can go through the documentation of CatBoost for a better understanding.
Goodbye to Hyper-parameter tuning?
CatBoost is implemented by powerful theories like ordered Boosting, Random permutations. It makes sure that we are not overfitting our model. It also implements symmetric trees which eliminate parameters like (min_child_leafs ). We can further tune with parameters like learning_rate, random_strength, L2_regulariser, but the results don’t vary much.
EndNote:
CatBoost is freaking fast when most of the features in your dataset are categorical. A model that is robust to over-fitting and with very powerful tools.
***Thank You***
0 Response to "Cat boost"
Post a Comment