
Ensemble Techniques:
An ensemble technique is a technique that combines the predictions from multiple machine learning algorithms together to make more accurate predictions than any individual model.
Random Forest is an ensemble technique which can be used for both regression and classification tasks. Random Forests basically combine the simplicity of decision tree with flexibility resulting in a vast improvement in accuracy. It is also called “Bagging”(Bootstrap Aggregation) and the main goal of the Random Forest is to reduce the variance of the decision tree.
Low Bias and High Variance: Over-fitting (this is where we use Random Forest to minimize the variance by splitting the data into chunks of features/data and train it).
Random Forest is used when our goal is to reduce the variance of a decision tree. Here idea is to create several subsets of data from the training samples chosen randomly with replacement. Now, each collection of subset data is used to train their decision trees. As a result, we end up with an ensemble of different models. Average of all the predictions from different trees are used which is more robust than a single decision tree.

Why Random Forest?
You might be wondering to ask why not just decision tree? It seems like the perfect classifier since it did not make any mistakes! A critical point to remember is that the tree made no mistakes on the training data. We expect this to be the case since we gave the tree the answers and didn’t limit the max depth (number of levels). The objective of a machine learning model is to generalize well to new data it has never seen before.
Over-fitting occurs when we have a very flexible model(the model has a high capacity) which essentially memories the training data by fitting it closely. The problem is that the model learns not only the actual relationships in the training data but also any noise that is present.
The reason the decision tree is prone to over-fitting when we don’t limit the maximum depth is that it has unlimited flexibility, meaning that it can keep growing until it has exactly one leaf node for every single observation, perfectly classifying all of them.
If you limit the maximum depth to 2 (making only a single split) in the decision tree, the classifications are no longer 100% correct. We have reduced the variance of the decision tree but at the cost of increasing the bias.
Decision trees are sensitive to the specific data on which they are trained. If the training data is changed (e.g. a tree is trained on a subset of the training data) the resulting decision tree can be quite different and in turn, the predictions can be quite different.
As an alternative to limiting the depth of the tree, which reduces variance (good) and increases the bias (bad), we can combine many decision trees into a single ensemble model known as the random forest.
How does Random Forest work?
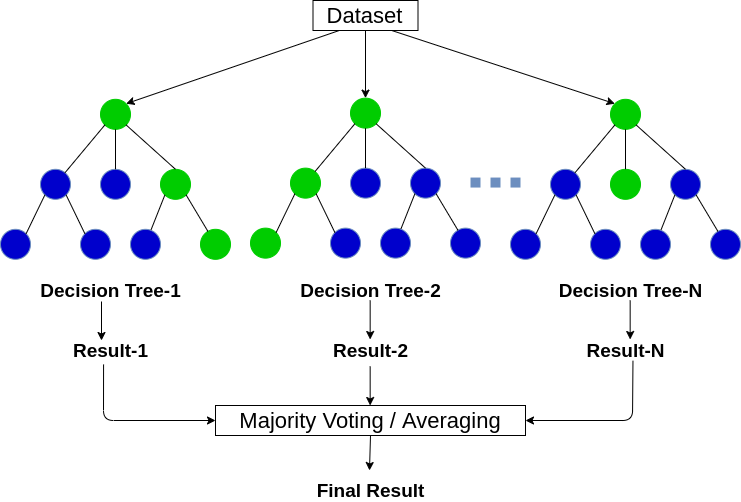
There are two stages in Random Forest algorithm, one is random forest creation, the other is to make a prediction from the random forest classifier created in the first stage.
Here the author firstly shows the Random Forest creation pseudocode:
- Randomly select “K” features from total “m” features where k << m
- Among the “K” features, calculate the node “d” using the best split point
- Split the node into daughter nodes using the best split
- Repeat the a to c steps until “l” number of nodes has been reached
- Build forest by repeating steps a to d for “n” number times to create “n” number of trees
In the next stage, with the random forest classifier created, we will make the prediction. The random forest prediction pseudocode is shown below:
- Takes the test features and use the rules of each randomly created decision tree to predict the outcome and stores the predicted outcome (target)
- Calculate the votes for each predicted target
- Consider the high voted predicted target as the final prediction from the random forest algorithm
The process is easy to understand, but it’s somehow efficient.
In the random forest, we grow multiple trees in a model. To classify a new object based on new attributes each tree gives a classification and we say that tree votes for that class. The forest chooses the classifications having the most votes of all the other trees in the forest and takes the average difference from the output of different trees. In general, Random Forest built multiple trees and combines them together to get a more accurate result.It can be used for both classification and regression problems.
How to choose number of trees to be included in the forest?
The only parameters when bagging decision trees is the number of samples and hence the number of trees to include.
This can be chosen by increasing the number of trees on run after run until the accuracy begins to stop showing improvement (e.g. on a cross-validation test harness). Very large numbers of models may take a long time to prepare, but will not over-fit the training data.
Applications of Random Forest (real-life):
Banking Sector: The banking sector consists of most users. There are many loyal customers and also fraud customers. To determine whether the customer is a loyal or fraud, Random forest analysis comes in. With the help of a random forest algorithm in machine learning, we can easily determine whether the customer is fraud or loyal. A system uses a set of a random algorithm which identifies the fraud transactions by a series of the pattern.
Medicines: Medicines need a complex combination of specific chemicals. Thus, to identify the great combination in the medicines, Random forest can be used. With the help of a machine learning algorithm, it has become easier to detect and predict the drug sensitivity of a medicine. Also, it helps to identify the patient’s disease by analyzing the patient’s medical record.
***Thank you***
0 Response to "Random Forest"
Post a Comment